Hivatkozás megjelenítése
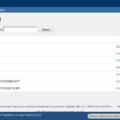
A Confluence-ben az oldalak és blogok létrehozása után a megadott címből generálódik az elérési út, pl: az "Ekezet nelkuli szoveg"-hez a "/display/COM/Ekezet+nelkuli+szoveg" olvasható elérés. Ez egészen addig jól működik, amíg rövid szöveget és angol karaktereket (pontosabban ASCII-t) használunk. A magyar ékezeteknél az elérési út a fenti könnyen olvasható megoldástól eltérően nem a cím, hanem csak egy pageId alapján tölti be a hivatkozott oldalt, pl: az "Ékezetes szöveg"-nél "/pages/viewpage.action?pageId=123456". Ennek az oldal használata közben nincs különösebb jelentősége, de ha linkelnénk egy külső oldalra vagy e-mailben küldjük, akkor szebb és olvashatóbb, ha látszik a cím (és a space: COM) is. Publikus szervereknél a keresési találatokhoz szükséges indexelés is jobb lehet egy olvasható linkkel (pl: Google találatok).
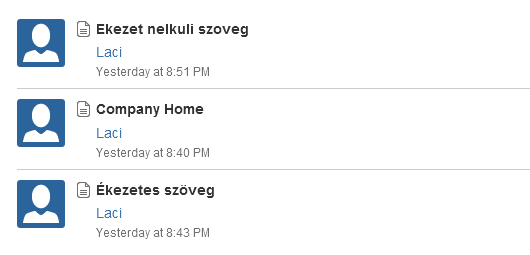
Az ékezetek normalizálása
A Page és a BlogPost osztály is az AbstractPage-ből származik, aminek a "getUrlPath()" metódusa adja azt a hivatkozást, amit a Confluence oldalakon láthatunk. Magát az URL generálást az innen meghívott GeneralUtil.getPageUrl(AbstractPage page) metódusa végzi két egymástól eltérő módon:
- toDisplayUrl: ha a cím (title) megfelelő és az adott oldal a legkésőbbi, akkor a "szép" URL-t adja
- getIdBasedPageUrl: ha ez nem teljesük, akkor a pageId szerintit
A feltételeket az "isSafeTitleForUrl()"-ben találjuk, melyek szerint:
- nem lehet a cím üres és 150 karakternél hosszabb
- nem végződhet írásjellel
- nem tartalmazhat illegális karaktereket: '+', '?', '%', '&', '"', '/', '\\', ';'
- nem lehet benne nem ASCII karakter
A magyar ékezetek pageId szerinti kezelését ez utóbbi okozza. A problémát a cím normalizálásával oldhatjuk meg:
private static String decompose(String input) {
return Normalizer.normalize(input, Normalizer.Form.NFD).replaceAll("\\p{InCombiningDiacriticalMarks}+", "");
}
Ékezetes oldal megjelenítése
A linkek beszédesé alakítása csak a feladat egyik része, mert ha így kattintunk rájuk, akkor nem tölti be a kívánt oldalt (PageNotFoundAction). Ennek oka, hogy a request-ek feldolgozásánál (PageAwareInterceptor) is két módon történik az adott oldal keresése: pageId vagy cím (+ space) alapján. A gondot az okozza, hogy az ékezetek nélküli linkből kivett cím (title) alapján nem lesz egyezés az adatbázisban az ékezetes címre. A legegyszerűbb megoldás, ha az ilyen normalizált URL-ek mellé betesszük a pageId-t is, így beszédes link mellett az oldal is egyértelműen azonosítható. Ennél szebb lenne, ha magát a DAO-t írnánk át, úgy hogy megtalálja az ékezetes rekordokat is (az ékezet nélküli címmel), de ezt majd a Confluence fejlesztők megoldják :)
GeneralUtil.java részlet
public static String getPageUrl(AbstractPage page) {
if (page == null || (page.getOriginalVersion() == null && page.getSpace() == null)) {
return "";
}
String title = page.getTitle();
// only use simple/nice page url if the page does not contain:
// - non-ASCII characters
// - '+' or '-' characters because these can be picked up by the insert and stripe through filters
// - double quotes (") because orion doesn't play nicely with them (CONF-1287)
// - ends in punctuation (CONFDEV-3995)
if (isSafeTitleForUrl(title) && page.isLatestVersion()) {
return toDisplayUrl(page);
} else if (isSafeTitleForNormalize(title) && page.isLatestVersion()) {
return toDisplayNormalizedUrl(page);
} else {
return getIdBasedPageUrl(page);
}
}
/**
* Get page URL that is id based (i.e. in the format /pages/viewpage.action?pageId=<pageId>)
* @param page the page to generate a url for
* @return page URL that is id based
*/
public static String getIdBasedPageUrl(AbstractPage page) {
if (page == null) {
return "";
}
return "/pages/viewpage.action?pageId=" + page.getId();
}
/**
* Is "title" something we can safely put in a /foo/bar/title URL? Or should we reference this thing by ID
* just to be safe?
* @param title The title to check
* @return True of the title can be put in a URL, false otherwise
*/
public static boolean isSafeTitleForUrl(String title) {
if (!isSafeTitleForNormalize(title)) {
return false;
}
for (int i = 0; i < title.length(); ++i) {
char c = title.charAt(i);
if (!isAscii(c))
return false;
}
return true;
}
private static boolean isSafeTitleForNormalize(String title) {
if (StringUtils.isEmpty(title) || title.length() >= 150) {
return false;
}
if (ENDS_WITH_PUNCTUATION.matcher(title).find()) {
return false;
}
if (".".equals(title)) {
return false;
}
for (int i = 0; i < title.length(); ++i) {
char c = title.charAt(i);
if (ILLEGAL_URL_TITLE_CHARS.contains(c)) {
return false;
}
}
return true;
}
/**
* This method is only ever called when we know that the page title consists of
* ASCII characters, so we only need to single-encode it, not double-encode.
* @param page The page to get the URL of
* @return The URL for the given page object
*/
private static String toDisplayUrl(AbstractPage page) {
return toDisplayUrl(page, false);
}
private static String toDisplayNormalizedUrl(AbstractPage page) {
return toDisplayUrl(page, true) + "?pageId=" + page.getId();
}
private static String toDisplayUrl(AbstractPage page, boolean normalize) {
StringBuilder displayUrl = new StringBuilder("/display/");
displayUrl.append(GeneralUtil.urlEncode(page.getSpace().getKey()));
displayUrl.append("/");
if ("blogpost".equals(page.getType())) {
//Why shouldn't a blog have any creation date? It happens in my case... Maybe a bug or so!
if (page.getCreationDate() != null) {
displayUrl.append(new SimpleDateFormat("yyyy/MM/dd").format(page.getCreationDate()));
displayUrl.append("/");
}
}
String title = normalize ? decompose(page.getTitle()) : page.getTitle();
displayUrl.append(urlEncode(title));
return displayUrl.toString();
}
private static String decompose(String input) {
return Normalizer.normalize(input, Normalizer.Form.NFD).replaceAll("\\p{InCombiningDiacriticalMarks}+", "");
}
Tesztelés
TestGeneralUtil.java részlet
public void testNonAsciiPageUrl() {
final String spaceKey = "HUN";
final String pageTitle= "Ékezetes szöveg";
Space space = new Space();
space.setKey(spaceKey);
Page page = new Page();
page.setSpace(space);
page.setTitle(pageTitle);
assertEquals("/display/" + spaceKey + "/Ekezetes+szoveg?pageId=0", GeneralUtil.getPageUrl(page));
}
A végeredmény
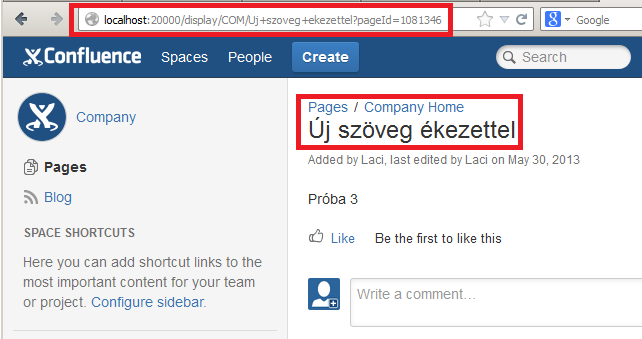
A meglévő 2 megoldás mellé létrehoztunk egy harmadik típusú link generálást. Az így kialakított kompromisszumos megoldás (beszédes hivatkozás pageId-val kiegészítve):
/display/COM/Uj+szoveg+ekezettel?pageId=1081346